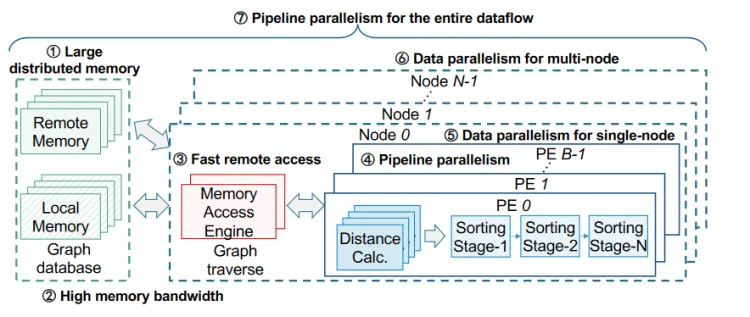
# 动机
CPU: 细粒度内存访问,线程数不足
GPU: 细粒度内存访问,内存容量小,缺乏流水线并行性(7)
# 挑战
- 随机细粒度访问
- 长时间远程访问延迟和沉重的通信开销
# 设计
# 内存访问引擎(Memory Access Engines, MAEs)
# 主要功能
- 特征打包内存访问(Feature-Packing Memory Access):
- MAEs 通过打包多个特征请求来提高内存访问的效率,增加内存带宽利用率。具体来说,它将多个小规模的内存访问请求合并为一个大规模的请求,从而减少内存访问的开销。
- 本地和远程内存访问优化:
- MAEs 优化了本地内存(如 DDR 和 HBM)和远程内存的访问,通过预取和延迟处理等技术减少访问延迟,提高数据传输效率。
- 数据预取和延迟处理:
- MAEs 实现了本地数据预取技术,在执行当前迭代时预取下一迭代所需的数据,从而隐藏内存访问延迟。
- MAEs 还实现了远程数据的延迟访问,通过合并多个远程请求,减少远程访问的频率和开销。
- 去重和同步:
- MAEs 包含去重模块,确保访问的节点和数据不重复,从而提高计算效率。
- MAEs 还包括同步模块,用于在多个 FPGA 节点之间同步数据和指令,确保分布式计算的一致性和协同工作。
# 设计特点
- 两级未完成请求生成(Two-Level Outstanding Request Generation):
- 通过在细粒度和粗粒度两个层次上合并未完成的内存请求,提高内存级并行性和带宽利用率。
- 将一个 PE 的所有节点请求合并
- 流水线优化(Pipeline Optimization):
- 采用任务级流水线技术,将内存访问、距离计算、排序等操作分解为多个子任务并行执行,从而减少每个迭代的总延迟。
- 本地数据预取(Local Data Prefetching):
- 在当前迭代期间预取下一迭代需要的数据,通过迭代间的数据打包减少延迟。
- 从本地 top-k 列表预测
- 远程访问优化(Remote Access Optimization):
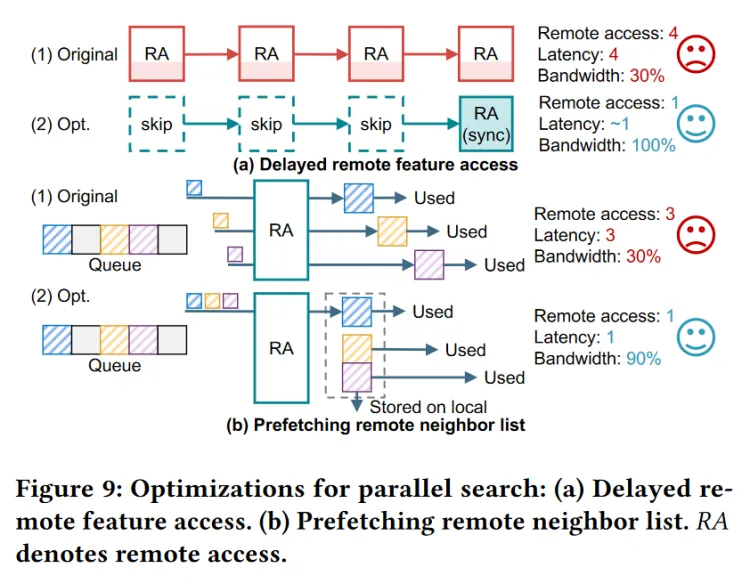
- 包括延迟远程特征访问和预取远程邻居列表技术,分别减少远程特征访问次数和远程访问延迟,提高远程内存访问的效率。
- (a)skip 挂起远程访问请求直到通信间隔
- (b) 请求一个远程节点的邻居列表时,将优先队列中所有属于这个远程节点的邻居列表都取回来
# MAEs 在 DF-GAS 架构中的位置
在 DF-GAS 架构中,每个 FPGA 节点内部包含多个 MAEs,每个 MAE 独立管理和优化内存访问。MAEs 与多个处理单元(PEs)协同工作,通过高带宽内存(HBM)和本地内存(DDR)进行数据传输,并通过网络接口与其他 FPGA 节点进行通信。
以下是 DF-GAS 架构图中 MAEs 的位置和组成部分:
------------------------------------------------
| FPGA Node |
|----------------------------------------------|
| ----------------------- ---------------- |
| | MAE | | PE | |
| | - Feature Packing | | - Distance | |
| | - Prefetching | | Compute | |
| | - Deduplication | | - Sorting | |
| ----------------------- ---------------- |
| ----------------------- ---------------- |
| | MAE | | PE | |
| | - Feature Packing | | - Distance | |
| | - Prefetching | | Compute | |
| | - Deduplication | | - Sorting | |
| ----------------------- ---------------- |
|----------------------------------------------|
| Network Interface |
------------------------------------------------
# 总结
MAEs(内存访问引擎)是 DF-GAS 架构中的重要组成部分,通过优化内存访问,提高内存带宽利用率和数据传输效率,从而显著提升系统性能。MAEs 通过特征打包、数据预取、延迟处理等技术,确保在大规模数据处理任务中实现高效的内存访问和数据管理。
# PE(Processing Element)
# 主要组件
- 距离计算单元(Distance Compute Unit, DCU):
- 功能:计算查询点与数据集中点之间的距离。
- 实现:采用流水线加法树结构,实现数据并行计算。每个 DCU 包含多个计算单元,通过寄存器和加法树将距离计算并行化。
- 本地 Top-K 排序单元(Local Top-K Sorting Unit, LSU):
- 功能:维护和更新本地 Top-K 候选点。
- 实现:使用优先队列结构,能够高效地插入和删除元素,保证在每次迭代后,距离最小的 Top-K 点保留在队列中。
- 全局 Top-K 排序单元(Global Top-K Sorting Unit, GSU, 可选):
- 功能:处理跨节点的 Top-K 结果合并。
- 实现:在分布式环境中,每个节点的 Top-K 结果需要最终合并成全局的 Top-K 结果。
- 控制器(Controller):
- 功能:管理和协调 PE 内部各个模块之间的操作。
- 实现:基于 RISC-V 兼容的指令集架构,能够灵活配置和调度 PE 的工作。
# PE 的工作流程
- 加载特征(Feature Loading):
- 从内存中加载当前迭代需要处理的特征向量。
- 距离计算(Distance Calculation):
- 使用距离计算单元(DCU)计算查询点与特征向量之间的距离。
- 更新 Top-K(Top-K Update):
- 将计算得到的距离插入到本地 Top-K 排序单元(LSU)中,维护一个有序的 Top-K 列表。
- 迭代处理(Iteration Processing):
- 继续下一个迭代,重复加载特征、距离计算和更新 Top-K 的过程,直到所有迭代完成。
- 结果合并(Result Merging):
- 如果是分布式系统,还需要使用全局 Top-K 排序单元(GSU)合并来自不同节点的 Top-K 结果。
# 设计细节
- 数据并行性(Data Parallelism):
- DCU 采用数据并行结构,通过多个计算单元并行处理多个数据点,提高计算效率。
- 流水线并行性(Pipeline Parallelism):
- PE 内部各个操作(如特征加载、距离计算、排序等)采用流水线并行方式,进一步减少每个迭代的总延迟。
- 优先队列结构(Priority Queue Structure):
- 本地 Top-K 排序单元(LSU)使用优先队列结构,确保能够高效地维护和更新 Top-K 候选点。
- 可扩展性(Scalability):
- 通过多个 PE 并行工作,并结合内存访问引擎(MAEs)优化内存访问,DF-GAS 架构能够高效处理大规模数据集。
# PE 设计示意图
------------------------------
| PE |
|----------------------------|
| Controller |
| - RISC-V compatible ISA |
|----------------------------|
| Distance Compute Unit |
| - Data Parallel Structure |
| - Pipelined Adder Tree |
|----------------------------|
| Local Top-K Sorting Unit |
| - Priority Queue Structure|
|----------------------------|
| Global Top-K Sorting Unit | (Optional)
| - Merging Results from |
| Different Nodes |
------------------------------
# 总结
PE(Processing Element,处理单元)在 DF-GAS 架构中负责关键的计算任务,包括距离计算和 Top-K 排序。通过数据并行和流水线并行技术,PE 能够高效地执行近似最近邻搜索中的计算操作,确保系统在处理大规模数据集时具有高性能和可扩展性。PE 与内存访问引擎(MAEs)协同工作,实现高效的内存访问和数据处理。
# 访问列表的硬件优化:HVR

HVR 利用 CRC-12 函数 [45] 生成哈希键,用于从 M 槽哈希表中读取出 M 个值。将输入 Nid 与 M 个值同时进行比较,以生成访问信号。如果 Nid 尚未被访问,则选择逻辑根据 M 个有效信号生成下一个插入位置(槽位号),然后将 Nid 插入目标槽。HVR 利用了 8 个带有 K = 1024 个桶的双端口 BRAMs 和 M = 4 个槽,将所需的芯片内存降低到 32KB。HVR 采用双缓冲技术来隐藏初始化的延迟,该延迟会在每次查询时发生。此外,HVR 中搜索和插入操作的延迟大约为每个节点 2-3 个周期。评估结果显示,平均冲突率约为 0.1%,导致几乎没有延迟开销(≤0.05%),并且没有准确性损失,因为冲突只会导致多余的访问而不会改变图遍历路径。